第二届东亚古籍数字人文国际研讨会于2023年10月27-29日在浙江省杭州市举行,会议由教育部长江学者浙江大学文学院徐永明教授主持的浙江大学文学院数字人文研究中心承办。在本次研讨会上国内外多位专家学者和头部企业做了关于古籍数字化发展和建设的主旨报告。报告专家立足于古籍传承保护,围绕古籍数字化建设过程中的“新材料,新方法,新问题,”为参会者带来一场盛大的学术盛宴。


开幕式
浙江大学文学院党委书记李铭霞主持开幕式,浙江大学党委常委、副校长黄先海教授向到场的各位专家学者致欢迎辞,预祝第二届东亚古籍数字人文国际研讨会顺利召开。接下来,中国古籍保护协会古籍智能开发与利用专委会主任王军教授讲话,并代表专委会向浙江大学校领导、浙江大学文学院对会议的大力支持表示由衷的感谢。

专家主旨报告

大模型时代的古籍研究工具展望:潜力与局限
上海图书馆馆长刘炜教授立足于上海图书馆的古籍数字化建设经验提出“平台+应用工具+知识库”形成算力联盟构建数据集合和语料库建设,形成架构灵活可拓展和支持社区共建迭代的数字人文服务平台。

古籍智能化与大语言模型训练
浙江大学徐永明教授介绍了当前存在的集中文献形态和数字人文前沿应用的技术手段,分析了智能化技术应如何赋能古籍数据开发和大语言模型训练的方向,同时以智慧古籍平台背景介绍了该平台建设的经验为古籍数字化平台建设提供思路和借鉴。

行尽中州数千里——我怎么做黄河与淮河间的明清水陆
台湾中山大学简锦松教授带领团队以明清古籍路程书与行记为资源定位古代道路,以早期地图与卫星影像定位明清都城,以实地GPS考察校正古代大小地名。运用古籍与现代技术相结合的方式助力古代地理文化知识的开发与保护,探索古代历史文化挖掘与保护的新思路。

人、地、时、空——历史数据的信息集成与实践
复旦大学的李旻老师介绍到,早在1998年他因为个人兴趣爱好建立个人知识数据平台,尝试用数据库记录相关文史知识,此数据记录的内容包括但不限于政治沿革地理数据、中国历史的政治框架、中国古代历法数据等。经过了二十多年的努力,建设了一个数据信息详实、数据体量庞大、检索数据方便快捷的数据网站平台。

大模型时代的智能文献学
北京大学王军教授指出人类信息环境演进到智能化阶段,从纸质文献到数字化信息环境再到网络化信息环境向智能化信息环境迈进,建设以大规模语言模型为基础的智能信息环境已势在必行。

韩国语言文字史及古籍数字化历程
韩国庆星大学许喆教授介绍了韩国汉语语言文字的使用沿革、韩国对汉字和古籍的认识历程、韩国古籍数字化的相关成果以及对古籍数字化建设的相关建议。

从数字化到智能化:特藏建设与利用
浙江大学黄晨教授在CADAL平台的基础上,提出数字人文背景下基于资源的学术研究平台的可持续发展模式,形成多来源、多形态、多资源的众包共建,实现古籍资源的可持续发展和利用。

数字人文时间基础设施:学理基础与应用案例
北京大学朱本军教授指出建设基于时序的数据关联和跨文明交流互鉴的时间基础设施为史学界研究提供有力工具,同时对于文史研究至关重要。

古典戏曲文本分析的问题导向与数据平台的建设思路
武汉大学程芸教授以古典戏曲文本分析问题为导向介绍数字平台建设思路,介绍到建设数字化数据库和智慧平台促进线上虚拟剧场与线下数字演艺剧场为数字化建设的主要思路。运用戏曲多模态形式进行平台建设以内容为中心构建统一标准探索平台建设新范式。

古籍的无创无损计算成像
北京师范大学Simon Mahony 教授报告了古籍保护过程中运用技术处理进行纸张的无损计算方法,介绍了光学相干断层扫描技术。这项技术的创新之处在于可以检测到颜料成分、不可见元素检测和表征,以及对墨水进行定量分析,有利于古籍原本的保护与数据开发。

多模态古文献知识库建设框架
上海图书馆夏翠娟老师报告了与大模型结合的知识库构建,目标向多模态古文献资料处理的数化转变,有利于推动知识库构建与古文献资源处理与利用。多模态向量数据库具有进行跨模态检索以及输出多模态结果的优势。运用现有古文献知识库建设方法和技术促进多模态古籍数据库建设,探索出一条呈现多模态古文献到向量知识库再到增强大模型的知识库构建路径。

中国古籍基础知识表示与构建
上海外国语大学的欧阳剑老师指出数智时代古籍应用不仅要面向用户,也要面向智能机器的阅读与理解。目前的GPT不能完整列举出事件,尤其是在检索古籍结果方面,仍存在局限性。因此欧阳剑老师多年来致力于构建古籍基础知识库,利用元数据、词表和知识分类体系构建古籍知识,利用机器学习模式挖掘古籍文献中的知识元,进行知识构建。
分会场报告

分会场一 自然语言处理研究与人才培养
- 浙江大学浙江大学杨春玲老师的报告主旨是古籍何以AI,汇报了古籍平台内在运作的模式。
- 韩国檀国大学崔至延和赵成德老师以字形为重要关注对象,研究历代韩国字形的变化构成和异体字定型问题。
- 西北大学刘睿教授针对异体字提出造字法的解决办法。
- 南京师范大学团队则介绍了“随园古汉语词法分析系统”,使用汉宇部件信息来增强古籍标点、分词、词性标注,结果精确度较高。
- 陈善雄老师关注手写体古籍文本检测方法。
- 尹琼老师将古籍数字化异体字处理提升到理论的高度并提出了一个原则和三个标准。
各位学者为参会者带来了一场精彩的头脑风暴。

分会场二 社会网络分析
- 浙江大学苑津山博士基于《清代朱卷集成》为数字化数据,研究科举人物社会网络关系,探索出一条将神经美学理论模型引入到文学理解路径。
- 邱诗雯老师通过绘制显著词语的分布图,讨论文气和事义。
- 中国人民大学梁继红老师汇报了家谱文献中的德行书写:以仙居吴氏宗谱为例的文本分析,通过主体词语标注的形式探究世人家族德行书写。
- 清华大学张琳越关注CBDB同名现象消歧探索,提出一系列有助于实现自动化消歧的建议。
各位学者的报告内容都指向社会关系网路,这是研究人文研究很重要的部分。

分会场三 东亚古籍数字化与智能化
- 上海图书馆杨敏老师介绍了上图馆藏特色数字文献资源建设,包括文献库、知识库、资源建设的工具和平台,并在数字人文视域下总结并展望未来的文史资源建设。
- 宋杰基于微信小程序“今秘阁-古文通止”进行成果介绍,为了让书写在古籍里的汉字活起来,在开发古文通止小程序时,紧紧围绕翻译的三个标准“信”“达“雅”,使单字辨识、字词释义和全文翻译更上一层楼。
- 上海交通大学汤萌围绕:如何丰富特藏资源的内涵、如何在数字化建设的基础上面向公众探索针对性的价值传播方法两方面,希望通过深度资源内涵提升图书馆在文化育人中的功能。
- 夏焱介绍了古籍智慧性保护与互联互通和理论构想,并在理论构想的基础上进行实践探索。他提出从建设大数据到建设智慧数据,使得智慧数据具有可推理、可计算、可发现、可行动的特点。
- 贤超法师介绍,经过OCR处理技术可以克服微调或重新训练的准确率低、“黑箱”机制、成本高、对于训练、标注和GPU要求高的缺点,推出异质多模型融合的探索。
- 王金英介绍到数字时代古籍活化的体系建构与价值表达,提出数字文献转录式创新发展,数字复制创新性发展,数字衍生重构式创新发展。
- 王媛媛做了题为黑龙江省古籍数字化整理问题及可行性路径研究的主旨报告,介绍黑龙江省古籍数字化程度低的现状。探析黑龙江省古籍数字化发展的制约性问题并提出可行性路径。
- 辽宁大学文学院朱祉璇和陈烨峰介绍了文学院院藏古籍编目,介绍辽宁大学古籍藏书现状,表达古籍数字化建设的展望。
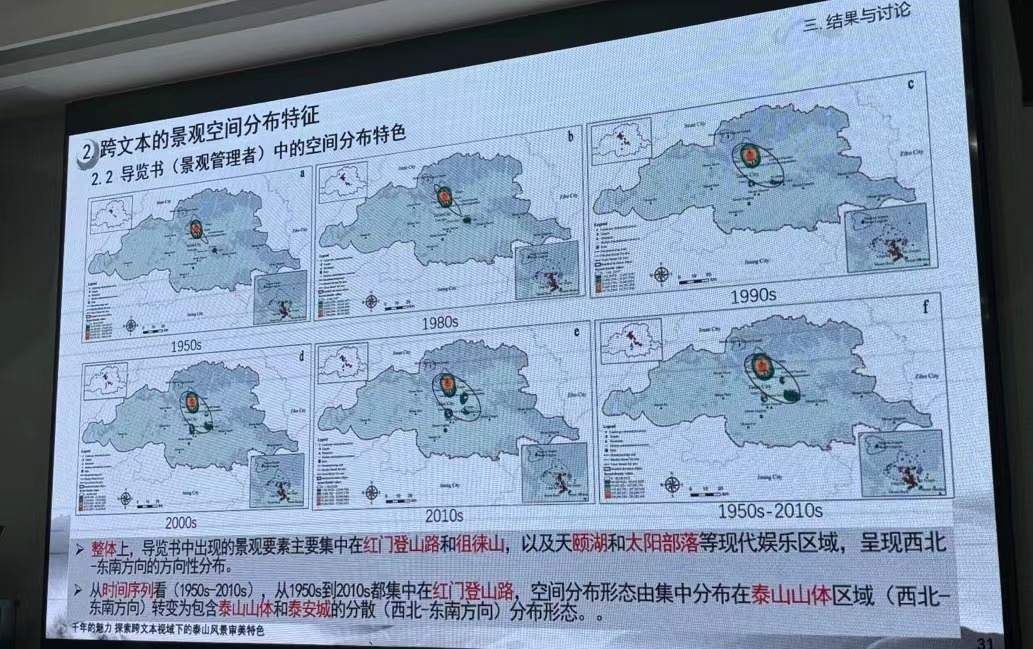
分会场四 地理分析与GIS
- 胡旭东做了关于宋代作家地理分布与可视化分析,并以《全宋诗》为考察对象,分析《全宋词》中收录的9200位作者的地理籍贯等特征,分析宋词创作的分期变化。
- 于莹运用数字技术对泰山的相关文本进行要素的提取以及聚类分析,并利用vosviewer等可视化呈探索文本视域下的泰山风景和审美特色,展现古都千年魅力。
- 伏红晓探究前清词人地理分布可视化分析,以CHGIS和QGIS等地理信息系统和定量分析方法对南大出版的《全清词》中的《顺康卷》《雍乾卷》 中的词人籍贯分布进行数据分析和可视化呈现。

分会场五 古籍数字化平台建设与数字化教学
- 中山大学图书馆面向智慧服务的契约文书基础数据建设,推动古籍数字化平台建设与数字化教学构建完整的数据建设体系与模式,用数字人文的工具进行分析提供GIS检索服务以交互式智慧展览的形式呈现。
- 蔡莹莹报告了古籍全流程智能研究平台的建设和应用,指出古籍全流程建设从数据管理、内容识别、知识抽取、知识图谱四方面推动古籍全流程智能研究落地应用。
- 国家图书馆赵大莹报告了《山海经》知识库的构建与实践,指出针对面对版本差异,体系不全,缺乏有数据标注的版本等问题,对专名等进行了标注结合标注后的数据,实现检索等功能。
- 南京农业大学李惠老师介绍了南京农业大学在数字人文课程建设和人才培养方面的经验。
- 湖南大学岳麓书院战蓓蓓做了文化数字化人才培养实践与构想,提出跨院科研教学合作以信科院和建筑院建设“数字人文”创新人才培养跨学科导师制研究构建书院知识图谱和虚拟复原历史建筑为例介绍文化数字人才培养经验。
- 葛怀东介绍了新时代古籍数字人才的培养的相关经验,梳理了古籍出版的发展的历程,分析了我国古籍数字化人才的培养现状。他认为古籍数字化人才培养应该打造一个数字化课程群,多专业联合培养。
- 王军教授总结认为,数字人文的发展还处于早期,此方面的人才培养具有高瞻远瞩的眼光。应该加深挖掘原始文献并结合前沿技术,实现实际应用场景的拓展。

分会场六 学术史与文化遗产数字化研究
- 江汉大学盛莉介绍了人工智能时代的古典文学研究,指出人工智能应用与人文社会科学的发展应为有三个阶段的过程——工具应用阶段、理论研究阶段、并行研究。引入计算机应用结束和计算思维赋能古典文学研究。
- 复旦大学王伟介绍元宇宙背景下的数字收藏与文化遗产传播,分析数字藏品的特征与发展现状,从四个维度看数字藏品对文化遗产传播的意义。
- 南京信息工程大学陆勇介绍了面向数字人文的古代方志物产语义化整理研究一以水稻品种资源为例,通过对于古籍进行细粒度的内容标识与提取,实现品种资源信息的语义化整理。
- 韩国高丽大学朴丽晶以韩国汉阳都城时光机为例子,展开数字时代对人文学本质的思考。简述韩国数字化过程和汉阳时光机语义数据库的构建流程,表达古文化数字开发的价值和意义。
- 浙江大学高荧通过应用古籍数据库的资源进行研究,探讨基于典籍文本的先秦两汉楼与阁意义辨析,是应用古籍数据库输出研究成果的案例之一。
- 福建师大郭菁和程文婷运用古籍数字库资源来探究中国传统汉服和剪纸艺术,是融合现代观点实现创造性转变创新性发展的典例。
- 宁波诺丁汉大学裘璐璐探究数字人文助力历史人文保护与传承,以宁波当地的文化资源为开发对象,服务于当地文博事业需求,助力当地人文历史传承和发展。
企业报告
- 字节跳动公司创建“识典古籍”公益免费古籍阅读平台,平台以古籍修复古籍数字化和古籍活化为主要任务。该平台具有界面简洁和使用效率高的特点,学者可以利用其进行底本对照、生成引用格式、繁简字转换等以及部分的文白对照,提高研究效率。平台关联了头条及抖音小程序,多平台进行阅读。
- 上海福呈公司的报告人分析了AGI的应用生态和技术,目前可以利用大语言模型进行文本处理分析、多模态、实体提取、AI著录辅助、检索增强生成、知识融合检索等。该公司结合上海图书馆进行了数字人文应用场景的探索,构建了云瀚AI助手。
- 上海双地公司分析了数字人文领域的知识图谱与大模型应用,以知识图谱赋能数字人文,将知识图谱进行可视化,配置管理能力以及多种布局。大模型可以进行智能检索、智能问答、绘画等多种方式应用。
- 杭州中元公司分享了对古籍保护的一些经验,比如书籍安全,在扫描时佩戴无指手套,在最大程度上保证生产过程数据安全。
- 汉王数字公司致力于新时代的古籍保护趋势正在从原生性保护向智慧传承性保护发展,提出古籍数据应该进行标准化,包括元数据、知识本体、基础数据设施标准化。
总结
中国古籍保护委员会古籍智能开发与利用专委会秘书长李斌老师做会议总结,用“高、大、全、新”四个特点来形容本次会议。会议的报告水准高、参会人员热情高、研究力量与合作前景特别大、古籍数字化领域全覆盖。从理论阐述到方案提出再到蓝图构想,覆盖古籍数字化领域的全方面:突出新理念、新设计、新尝试、新平台。会议立足国际视野推动东亚古籍数字化建设,加强合作开拓探索积极推动古籍数字库技术和平台的构建,最终实现古籍智能开发与利用的美好愿景。

闭幕式
浙江大学文学院院长冯国栋教授致闭幕辞,庆祝第二届东亚古籍数字人文国际研讨会成功举办,向各位进行报告的专家学者表示由衷的感谢。
冯国栋院长表示新技术新载体的兴起需要我们对新载体进行重新认识,载体对于传承文明有着重要的作用,新的思考和旧的怀恋都是源于对文明传承与保护的初衷。面对数字人文引发新的变革要理性认识清晰看待。徐永明教授致辞讲话,感谢各位专家学者带来的精彩报告,感谢各联合主办单位的大力支持和各个公司的大力赞助和浙江大学领导的支持。最后徐永明教授宣布第二届东亚古籍数字人文国际研讨会顺利闭幕。


主办单位
浙江大学文学院数字人文研究中心
联合主办
北京大学数字人文研究中心
南京师范大学文学院
韩国檀国大学汉文教育研究所
杭州云四库科技有限公司
浙江大学文史大数据实验室
北京大学-字节跳动数字人文开放实验室
特别鸣谢
本次会议举办期间,获得以下单位的鼎力支持,在此表 示真挚感谢!(排名不分先后)
北京大学-字节跳动数字人文开放实验室
上海图情信息有限公司
杭州中元数据科技有限公司
北京汉王数字科技有限公司
上海福呈数据科技有限公司
上海双地信息系统有限公司
北京书同文电脑技术开发有限责任公司
相关链接:DHEA2023东亚古籍数字人文国际研讨会